ColPaliとは?視覚言語モデルで文書検索を革新!ViDoReベンチマークで高精度を実証
最新の視覚言語モデルColPaliが文書検索を革新!図表やレイアウトも理解し、ViDoReベンチマークで高精度を達成。従来のテキストベースの手法を凌駕するColPaliの仕組み、活用例、今後の展望を解説します。

- プロンプトの送信回数:4回
- 使用したモデル:GPT-4o, Gemini 1.5 Pro
AIとデジタルイノベーションでビジネスを変える時が来ました。
私たちと一緒に、効果的なマーケティングとDXの実現を目指しませんか?
弊社では、生成AI開発やバーチャルインフルエンサーの運用について無料相談を承っております。
お打ち合わせではなくチャットでのご相談もお待ちしております。

目次
- ColPaliとは?視覚言語モデルで文書検索を革新!
- 従来手法の限界:テキスト中心主義からの脱却
- ViDoReベンチマーク:視覚的文書検索の真価を問う
- ColPaliのアーキテクチャ:PaliGemma-3Bを基盤とした革新
- ColPaliの性能:既存手法を圧倒する検索精度
- ColPaliの解釈可能性:ブラックボックスからの脱却
- アブレーション研究:ColPaliの構成要素を徹底検証
- ColPaliの多言語対応:ColQwen2による中国語検索
- ColPaliの実用性:高速推論と省メモリ設計
- 今後の展望:RAGへの応用と更なる進化
この記事は、AI(人工知能)によって生成されたものです。
内容は専門家による監修や校正を経ておらず、AIの現在の能力と知識ベースに基づいています。
したがって、記事の内容には限界があり、専門的な意見や最新の情報を代替するものではありません。
読者は、この記事を参考の一つとして用いることを推奨し、必要に応じて専門家の意見を求めることをお勧めします。
以下から、AIライターの執筆が始まります。
ColPaliとは?視覚言語モデルで文書検索を革新!
デジタル社会において、膨大な文書から必要な情報を探し出すことは、日々の業務から学術研究まで、あらゆる活動の基盤となっています。しかし、既存の文書検索システムはテキスト中心の設計となっており、図表、レイアウト、フォントといった視覚情報が重要な役割を果たす現代の文書を十分に扱うことができていませんでした。今回ご紹介するColPaliは、視覚言語モデル(VLM)の力を駆使することで、この課題を突破する画期的な文書検索手法です。論文「ColPali: Efficient Document Retrieval with Vision Language Models」(arXiv:2407.01449v3)とHugging Faceのプロジェクトページの内容に基づき、ColPaliの技術的詳細、圧倒的な性能、そしてその広大な応用可能性について解説していきます。

ついに視覚情報をここまで活用できる時代になったんですね!今後の情報検索の在り方が大きく変わりそうです。
従来手法の限界:テキスト中心主義からの脱却
従来の文書検索システムは、PDFパーサーやOCR (光学文字認識) を用いてテキスト情報を抽出し、キーワードマッチングやTF-IDFなどの手法で検索を行っていました。しかし、このアプローチには、複雑な前処理が必要、視覚情報の欠落、コンテキスト理解の不足といった限界がありました。例えば、「apple」という単語が果物を指すのか、企業を指すのかを判断することができませんでした。
ColPaliは、これらの限界を克服するために、VLMを用いて文書ページの画像から直接埋め込みベクトルを生成する手法を採用しています。これにより、複雑な前処理を不要とし、視覚情報を含めた文書全体のコンテキストを理解した検索が可能になります。
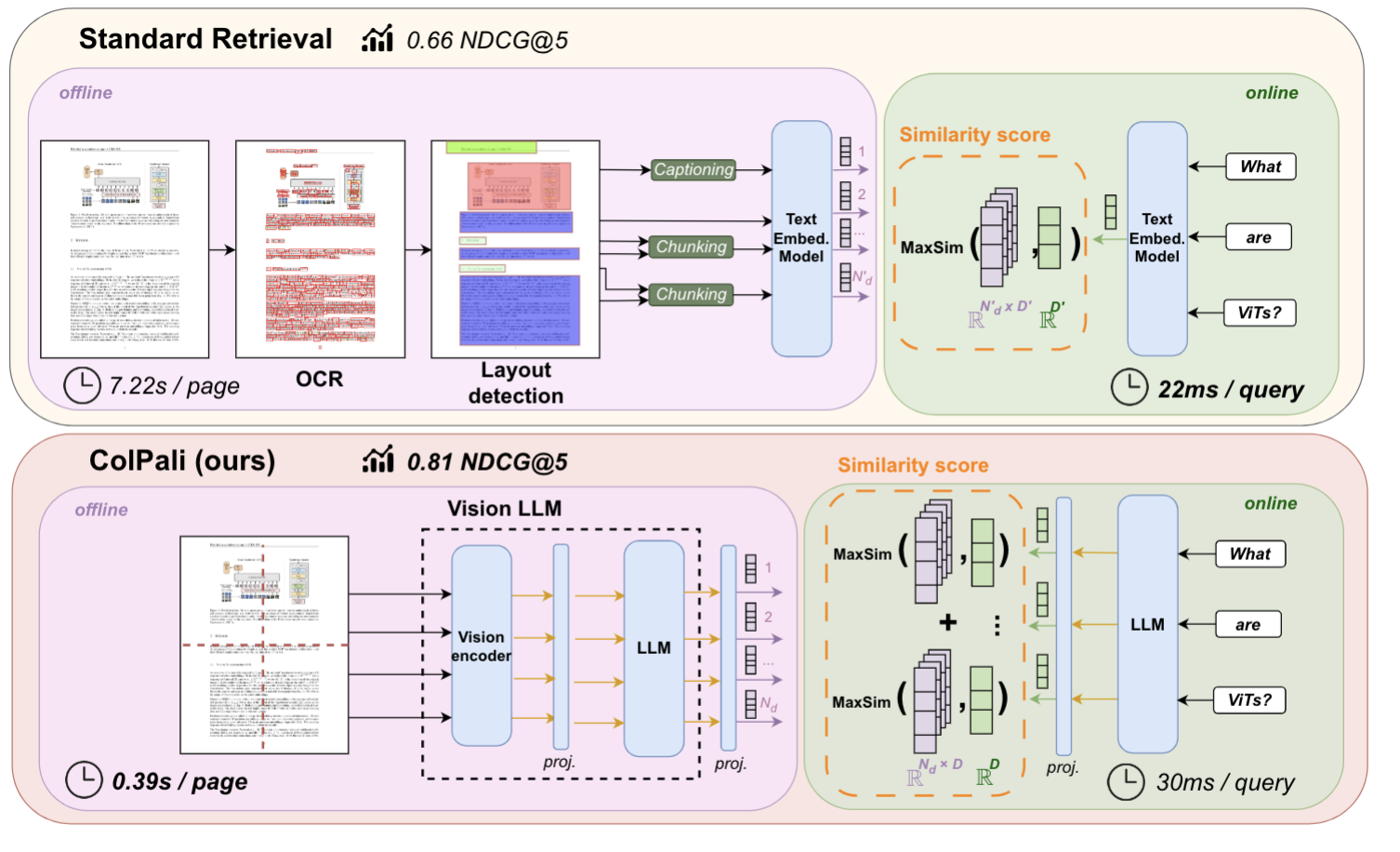
OCRの精度に悩まされることもなくなりそうですね。視覚情報を直接扱うことで、検索の精度が飛躍的に向上しそうです。
ViDoReベンチマーク:視覚的文書検索の真価を問う
ColPaliの性能を評価するために、多様なデータセットから構成されるViDoReベンチマークが構築されました。ViDoReは、学術的なデータセット(DocVQA, InfoVQA, TAT-DQA, ArxivQA, TabFQuAD)に加え、実世界のRAGシナリオを想定した実践的なデータセット(Energy, Government, Healthcare, AI, Shift Project)を含んでいます。これらのデータセットは、テキスト、図表、レイアウトなど、多様なモダリティの情報を網羅しており、ColPaliの包括的な性能評価を可能にしています。
各データセットの詳細は、hugging faceのデータセットカードで確認できます。データセットの規模、ドメイン、言語、タスクの種類などが詳細に記載されており、ViDoReベンチマークの多様性と網羅性を理解する上で非常に役立ちます。
多様なデータセットで評価されている点は信頼できますね。実世界のRAGシナリオを想定したデータセットが含まれているのもポイント高いです。
ColPaliのアーキテクチャ:PaliGemma-3Bを基盤とした革新
ColPaliは、PaliGemma-3Bと呼ばれる高性能なVLMを基盤として、文書ページの画像から直接コンテキスト化埋め込みを生成します。PaliGemma-3Bは大規模な画像とテキストのペアデータセットで学習されており、画像とテキストの対応関係を理解する能力に優れています。ColPaliは、PaliGemma-3Bの出力をColBERTスタイルのマルチベクトル表現に変換することで、文書内の各要素(単語、図表、レイアウトなど)のコンテキストを詳細に捉えます。さらに、遅延相互作用マッチングメカニズムを用いることで、クエリと文書の各要素間の相互作用を考慮した高精度な検索を実現しています。Hugging Faceのページでは、ColPaliの学習済みモデルが公開されており、誰でも簡単に利用できます。モデルカードには、モデルのアーキテクチャ、学習データ、ハイパーパラメータ、性能評価結果などが詳細に記載されています。
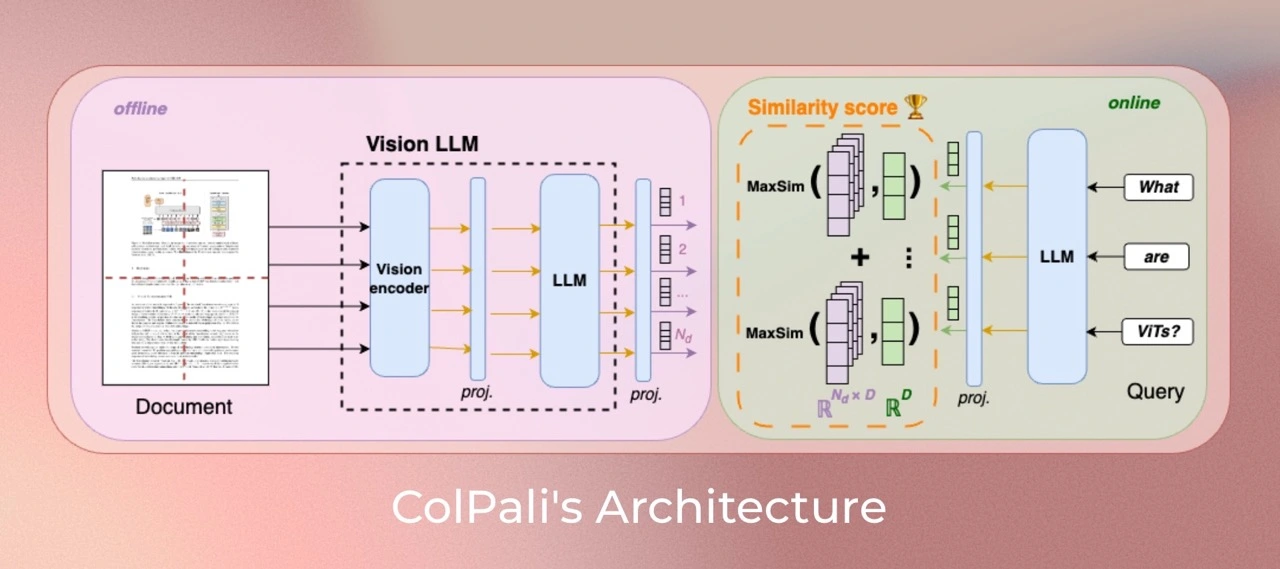
ColPaliのアーキテクチャは、VLMと遅延相互作用の組み合わせにより、高精度かつ効率的な文書検索を実現する洗練された設計ですね。公開されているモデルを使って、実際に試してみたくなりました!
ColPaliの性能:既存手法を圧倒する検索精度
ViDoReベンチマークを用いた評価の結果、ColPaliは、NDCG@5、Recall@1といった指標において、既存のテキストベースの手法や対照VLMベースの手法を大きく上回る性能を示しました。これは、ColPaliが視覚情報を効果的に活用し、文書全体のコンテキストを理解することで、高精度な検索を実現していることを示しています。論文では、Unstructuredを用いたベースライン(Text only, +OCR, +Captioning)との比較も行われており、ColPaliが大幅な性能向上を実現していることが示されています。特に、キャプション生成を用いる手法は計算コストが高いにも関わらず、ColPaliほどの性能向上は得られていません。Hugging Faceのリーダーボードでは、様々なモデルの性能を比較することができます。ColPaliは、多くのタスクでトップクラスの性能を達成しており、その実力の高さが証明されています。
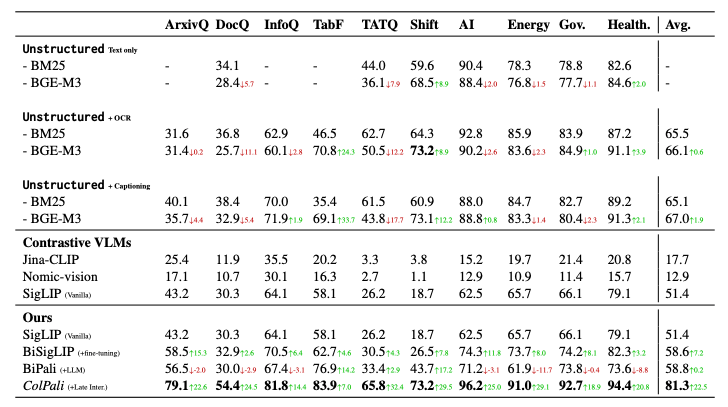
既存手法を大きく上回る性能は印象的ですね!キャプション生成よりも効率的に高精度を実現している点も注目です。
ColPaliの解釈可能性:ブラックボックスからの脱却
ColPaliは、類似度マップを可視化することで、モデルがどの画像パッチに注目しているかを理解することができます。これにより、ColPaliが単にテキストを認識するだけでなく、図表やレイアウトなどの視覚的コンテキストを理解していることが明らかになります。論文では、いくつかの例を用いて類似度マップの可視化結果を示しており、ColPaliがクエリに関連する視覚的要素を的確に捉えていることが分かります。
類似度マップの可視化は、モデルの解釈性を高める上で非常に重要ですね。ブラックボックスではなく、どのようなロジックで検索結果を出力しているのか理解できるのは大きなメリットです。
アブレーション研究:ColPaliの構成要素を徹底検証
論文では、ColPaliの各構成要素の重要性を検証するために、詳細なアブレーション研究が行われています。パッチ数やモデルサイズの影響、ビジョンコンポーネントのファインチューニング、クエリ拡張トークンの効果、損失関数の比較など、様々な観点から分析が行われています。これらの研究により、ColPaliの設計の最適性と、各要素の貢献度が明らかになっています。
徹底的なアブレーション研究は、モデルの改善点を明確にする上で重要ですね。今後のColPaliの進化にも期待が高まります。
ColPaliの多言語対応:ColQwen2による中国語検索
Hugging Faceのページでは、ColPaliに加えて、ColQwen2と呼ばれる中国語特化のモデルも公開されています。ColQwen2は、ColPaliのアーキテクチャを中国語のVLMであるQwen-VLに適用したもので、中国語文書に対する高精度な検索を可能にします。多言語対応は、グローバルな情報アクセスを促進する上で非常に重要な要素です。

中国語対応モデルの登場は、多言語情報アクセスを大きく前進させるでしょう。他の言語への展開にも期待が持てますね。
ColPaliの実用性:高速推論と省メモリ設計
ColPaliは、実世界のアプリケーションでの利用を想定して設計されており、高速な推論と低いメモリ使用量を実現しています。遅延相互作用マッチングメカニズムや埋め込みベクトルの次元数削減など、様々な工夫が凝らされています。Hugging Faceのページでは、ColPaliの推論コードが公開されており、誰でも簡単に試すことができます。
高速推論と省メモリ設計は、実用性を高める上で非常に重要ですね。手軽に試せるコードが公開されているのもありがたいです。
今後の展望:RAGへの応用と更なる進化
ColPaliは、RAGをはじめとする様々なアプリケーションで大きな可能性を秘めています。例えば、ColPaliを用いることで、図表や画像を含む複雑な文書から必要な情報を効率的に抽出することが可能になります。今後の研究開発としては、より多様な文書形式への対応、対照学習による事前学習、低品質画像への対応、視覚に基づく質問応答との統合などが挙げられます。
ColPaliとViDoReは、視覚言語モデルを用いた文書検索の新たな可能性を示す、画期的な成果ですね。今後の発展に注目です!



