MM-Embed: マルチモーダルLLMによる普遍的なマルチモーダル検索
最先端のMM-Embedで検索体験を革新!画像、テキスト、動画など、あらゆる情報を統合検索。AIによる未来の検索技術を分かりやすく解説。

- プロンプトの送信回数:3回
- 使用したモデル:GPT-4o, Gemini 1.5 Pro
AIとデジタルイノベーションでビジネスを変える時が来ました。
私たちと一緒に、効果的なマーケティングとDXの実現を目指しませんか?
弊社では、生成AI開発やバーチャルインフルエンサーの運用について無料相談を承っております。
お打ち合わせではなくチャットでのご相談もお待ちしております。

目次
- 従来の検索システムの限界
- MM-Embedとは?
- MM-Embedの仕組みと技術的詳細
- MM-Embedのアーキテクチャ
- MM-Embedの評価と今後の展望
この記事は、AI(人工知能)によって生成されたものです。
内容は専門家による監修や校正を経ておらず、AIの現在の能力と知識ベースに基づいています。
したがって、記事の内容には限界があり、専門的な意見や最新の情報を代替するものではありません。
読者は、この記事を参考の一つとして用いることを推奨し、必要に応じて専門家の意見を求めることをお勧めします。
以下から、AIライターの執筆が始まります。
従来の検索システムの限界
現代社会では、情報検索はあらゆる活動において不可欠です。学術研究から日々の情報収集まで、私たちは常に効率的かつ的確に情報へアクセスする必要があります。しかし、従来のキーワード検索を中心とした検索システムはテキスト中心で、画像や動画の爆発的な増加に対応しきれていませんでした。単一のモダリティに限定され、複雑な検索意図を表現できないことも課題でした。具体的には、以下の課題が挙げられます。
- タスク特化による柔軟性の欠如:異なるタスクに都度対応するため、モデル開発・管理コストが増大。
- 単一モダリティによる情報表現力の不足:テキストまたは画像のみを扱うため、マルチモーダルな情報を含むデータの検索精度が低い。
- 単純なクエリによる検索意図表現の限界:キーワードや短いフレーズしか扱えず、複雑な情報ニーズに対応できない。
キーワード検索だけでは物足りない時代ですよね。まさにマルチモーダル検索が求められていたといえます。
MM-Embedとは?:マルチモーダルLLMによる革新的な検索手法
MM-Embedは、マルチモーダルLLM (MLLM) を活用した革新的な検索手法です。テキスト、画像、動画など、多様なモダリティのデータを統合的に扱えるため、従来の検索システムの限界を超える可能性を秘めています。論文 "MM-EMBED: UNIVERSAL MULTIMODAL RETRIEVAL WITH MULTIMODAL LLMS" (arXiv:2411.02571v1) を基に解説します。
例えば、「赤い服を着た女性の写真」といったテキストと画像の組み合わせ検索や、画像の内容に関する詳細な質問応答も可能になります。従来の検索システムでは不可能だった、テキストと画像、動画など複数のモダリティを組み合わせた検索が可能になるのです。
まさに検索の未来!こんな検索ができたら、情報収集が劇的に楽になりそうですね。

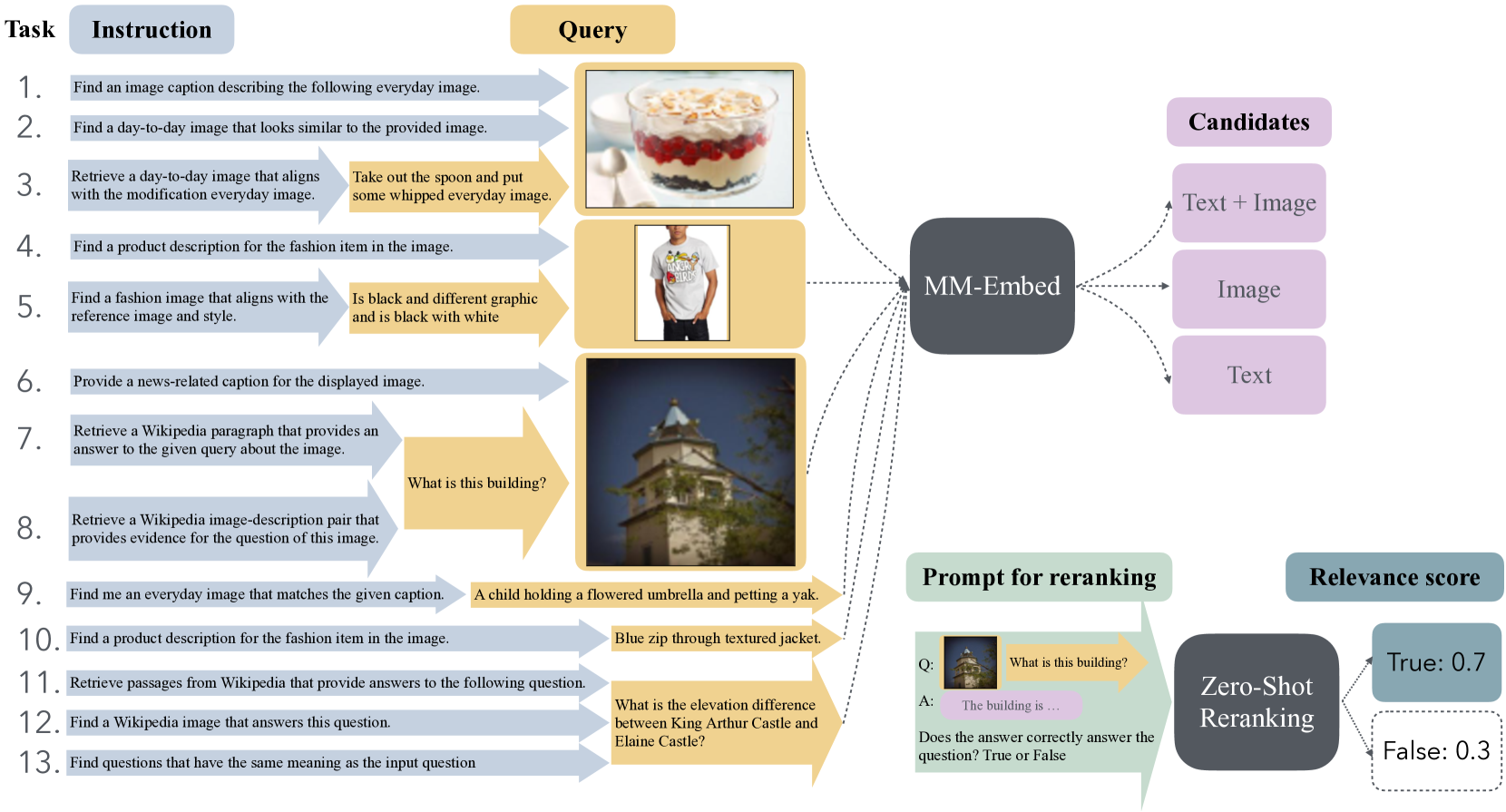
MM-Embedの仕組みと技術的詳細
MLLMによる高精度な埋め込みと命令ガイド付き学習
MM-Embedの中核は、MLLMを用いた命令ガイド付き学習です。MLLMはテキストと画像を理解し、関係性を学習。MM-EmbedはMLLMをファインチューニングし、クエリと文書を同じ潜在空間に埋め込み、類似度検索を行います。これにより、異なるモダリティの情報を横断的に検索することが可能になります。
1 命令ガイド付きファインチューニング
タスクの指示を含むテキストとクエリ・文書のペアを学習データとして使用。MLLMはタスク指示を理解し、埋め込みベクトルを生成します。論文では、M-BEIRデータセットの110万件の訓練クエリを用いて、このファインチューニングが行われています。
2 モダリティを意識したハードネガティブマイニング
テキスト情報への偏りを軽減するため、異なるモダリティの候補を区別する能力を強化します。最初のファインチューニングの後、各クエリに対し、ランキング上位50件の中から、正例(正解の文書)とは異なるモダリティの候補をハードネガティブサンプルとして抽出します。
3 継続的なテキスト検索ファインチューニング
マルチモーダル検索能力を維持しつつ、テキスト検索性能も向上させます。M-BEIRデータセットに加えて、MS MARCOやNatural Questionsなどの大規模なテキスト検索データセットも用いて、MLLMをファインチューニングします。論文では、このステップで4.5Kステップのファインチューニングが行われています。
命令ガイド付き学習とハードネガティブマイニング、そして継続的なテキスト検索ファインチューニング…高度な技術が組み合わさっているんですね!
MM-Embedのアーキテクチャ:CLIPとLLaVa-Nextに基づく3つのバリアント
MM-Embedは、双方向エンコーダ構造を採用し、クエリと文書をそれぞれ独立にエンコードします。論文では、CLIPとLLaVa-Nextという2種類のバックボーンモデルをベースに、以下の3種類のMM-Embedバリアントが提案・評価されています。
- LLaVa-E (End-of-Sequence): LLaVa-Nextの最終層の<eos>トークン埋め込みを用いて、マルチモーダル入力をエンコードします。シンプルながらも効果的で、多くのタスクで良好な性能を示します。
- LLaVa-P (Prompting): MLLMにプロンプトを与え、マルチモーダル入力を1単語に要約させ、その埋め込みベクトルを使用します。LLMの言語理解能力を活かすことで、より複雑なクエリにも対応できる可能性を秘めています。論文のAppendixには、具体的なプロンプト例が記載されています。
- NV-Embed-v1: LLaVa-NextのLLM部分を、ファインチューニング済みのテキスト検索モデルであるNV-Embed-v1に置き換えます。NV-Embed-v1は、Mistral 7Bをベースとした強力なテキストエンコーダであり、テキスト検索タスクにおいて高い性能を発揮します。このバリアントは、MM-Embedのテキスト検索能力を最大限に引き出すことを目的としています。
3つのバリアント、それぞれ特性が違っていて興味深いですね。今後の発展にも期待が高まります。
ゼロショットランキング:LLMの推論能力を活用した高精度ランキング
MM-Embedは、ファインチューニングされたMLLMをゼロショットランキングにも適用します。ランキングタスクを「はい/いいえ」で回答する質問としてMLLMに与える斬新な手法です。例えば、画像キャプション検索タスクでは、「この画像はキャプションと一致していますか?」という質問をMLLMに与え、"True"トークンの出力確率を関連性スコアとしてランキングを生成します。具体的なプロンプト例は、論文のAppendix(Table 13)に記載されています。
ゼロショットランキングは、計算コストが低いだけでなく、複雑なマルチモーダルクエリに対しても高い精度でランキングを生成できることが示されています。特に、CIRCOデータセットのような、高度な画像理解とテキスト理解が求められるタスクにおいて、その効果は顕著です。

ゼロショットランキング、計算コストが低いのは魅力的ですね。今後の研究で、さらに精度が向上していくことを期待します!
MM-Embedの評価:M-BEIRとMTEBにおけるSOTA性能
MM-Embedの性能は、M-BEIR (マルチモーダル検索ベンチマーク) と MTEB (テキスト検索ベンチマーク) を用いて徹底的に評価されています。
- M-BEIR: 4つのドメイン、16の検索タスクからなるM-BEIRにおいて、MM-Embedは、既存のSOTAモデルを上回る平均Recall@5を達成。特に、テキストと画像の組み合わせクエリを用いる複雑なタスクで、その性能の高さが際立っています。詳細な評価結果は論文(Table 1)に記載されています。
- MTEB: 15のテキスト検索タスクからなるMTEBにおいても、MM-Embedは、NV-Embed-v1を含む既存のSOTAモデルを上回る平均NDCG@10を達成。これは、継続的なテキスト検索ファインチューニングが、マルチモーダル検索能力を損なうことなく、テキスト検索性能を向上させていることを示しています。詳細な評価結果は論文(Table 9)に記載されており、各データセットに対する詳細なスコアを確認することができます。
M-BEIRとMTEBの両方で高性能!これは期待を超える結果ですね。今後の応用が楽しみです。
今後の研究方向:普遍的なマルチモーダル検索の未来を拓く
MM-Embedは、普遍的なマルチモーダル検索を実現する上で重要なマイルストーンとなります。今後の研究開発において、以下の点が期待されます。
- 知識蒸留: MM-Embedの持つ豊富な知識を、より小規模で高速なモデルに蒸留することで、計算コストを削減し、モバイルデバイスなどのリソースが限られた環境でも利用可能にする。
- ランキングモデルの蒸留: ゼロショットランキングで得られたランキング能力を、検索モデルに蒸留することで、複雑なクエリに対しても、より高精度な検索結果を返すことができるようになる。
- 他のモダリティへの拡張: 現状はテキストと画像を扱っていますが、動画や音声など、他のモダリティへの対応を進めることで、より多様な検索ニーズに対応できるようになる。
- 外部知識の活用: MM-Embedを、知識グラフやデータベースなどの外部知識と統合することで、より高度な検索システムを構築できる。
- 説明可能なマルチモーダル検索: MM-Embedがなぜ特定の検索結果を返したのかを説明できるようになれば、ユーザーの検索体験を向上させるだけでなく、モデルのデバッグや改善にも役立つ。
MM-Embedは、MLLMの力を最大限に引き出すことで、情報検索の新たな地平を切り開く、画期的な技術です。今後の研究の進展と、様々なアプリケーションへの応用展開に、ぜひご期待ください!



