Document Screenshot Embedding(DSE) によるマルチモーダル検索の統一:検索の未来を垣間見る
ドキュメントスクリーンショット埋め込み (DSE) でマルチモーダル検索が進化!画像、テキスト、表など、あらゆる情報をスクリーンショット一つで検索可能に。AI技術を活用したDSEの仕組み、メリット、今後の展望を解説します。

- プロンプトの送信回数:5回
- 使用したモデル:GPT-4o, Gemini 1.5 Pro
AIとデジタルイノベーションでビジネスを変える時が来ました。
私たちと一緒に、効果的なマーケティングとDXの実現を目指しませんか?
弊社では、生成AI開発やバーチャルインフルエンサーの運用について無料相談を承っております。
お打ち合わせではなくチャットでのご相談もお待ちしております。

目次
- DSEとは?マルチモーダル検索の進化
- 従来手法の限界とDSEの登場
- DSEの心臓部:大規模ビジョン言語モデル (LVLM) の活用
- 視覚エンコーダの進化:パッチ分割とPhi-3-visionの採用
- 対照学習による最適化:InfoNCE損失で精度向上
- 妥協なき検証:多様なデータセットによる徹底評価
- ゼロショット学習:汎化性能の高さを実証
- パッチサイズと処理速度のトレードオフ:最適なバランスを探る
- ケーススタディ:アテンションの可視化による動作解析
- エラー分析:更なる改善に向けた課題
- ビジネスインパクト:様々な分野での応用可能性
- 今後の展望:更なる進化と社会実装への期待
この記事は、AI(人工知能)によって生成されたものです。
内容は専門家による監修や校正を経ておらず、AIの現在の能力と知識ベースに基づいています。
したがって、記事の内容には限界があり、専門的な意見や最新の情報を代替するものではありません。
読者は、この記事を参考の一つとして用いることを推奨し、必要に応じて専門家の意見を求めることをお勧めします。
以下から、AIライターの執筆が始まります。
DSEとは?マルチモーダル検索の進化
情報検索の分野では、常に効率性と網羅性の両立が課題となっています。従来の手法では、異なるモダリティ(テキスト、画像、表など)を個別に処理する必要があり、手間や情報損失のリスクが伴っていました。今回ご紹介するドキュメントスクリーンショット埋め込み (DSE) は、これらの課題を一挙に解決する画期的なアプローチです。スクリーンショットを単一の入力形式として扱うことで、前処理の必要性を排除し、視覚的コンテキストを含むあらゆる情報を保持したまま検索を可能にします。まるで人間の認知能力に近づいたかのような、この革新的な技術を、論文 "Unifying Multimodal Retrieval via Document Screenshot Embedding" (arXiv:2406.11251v1) を紐解きながら、詳細に解説していきます。
まさに未来の検索体験!スクリーンショット一枚で、必要な情報へダイレクトアクセス。情報検索の常識が覆される日も近いかもしれません。
従来手法の限界とDSEの登場
既存の検索システムは、文書のモダリティごとに異なる処理を必要としていました。例えば、テキスト検索にはキーワードマッチングやTF-IDF、画像検索には画像特徴量の比較などが用いられます。これらの手法を組み合わせることでマルチモーダル検索を実現することも可能ですが、処理の複雑さや情報損失は避けられませんでした。特に、文書のレイアウトや視覚的コンテキストといった情報は、従来の手法では十分に活用できていませんでした。
DSEは、まさにこの問題に対する解となる技術です。スクリーンショットを用いることで、あらゆるモダリティを単一の形式に統合し、LVLMの力を最大限に引き出すことを可能にしました。これにより、従来の手法では不可能だった、視覚的コンテキストを考慮した高精度な検索が実現されます。

DSEはマルチモーダル検索のゲームチェンジャー!異なるモダリティを統合処理することで、これまで不可能だった検索体験を実現しています。今後の発展に非常に期待しています。
DSEの心臓部:大規模ビジョン言語モデル (LVLM) の活用
LVLMとは?
DSEの中核を担うのは、近年のAI技術の飛躍的な進歩を象徴するLVLMです。LVLMは、画像とテキストの両方を理解し、その関係性を捉えることができる強力なモデルです。DSEでは、このLVLMを用いてスクリーンショットをベクトル表現に変換することで、画像とテキストの情報を統合的に表現します。
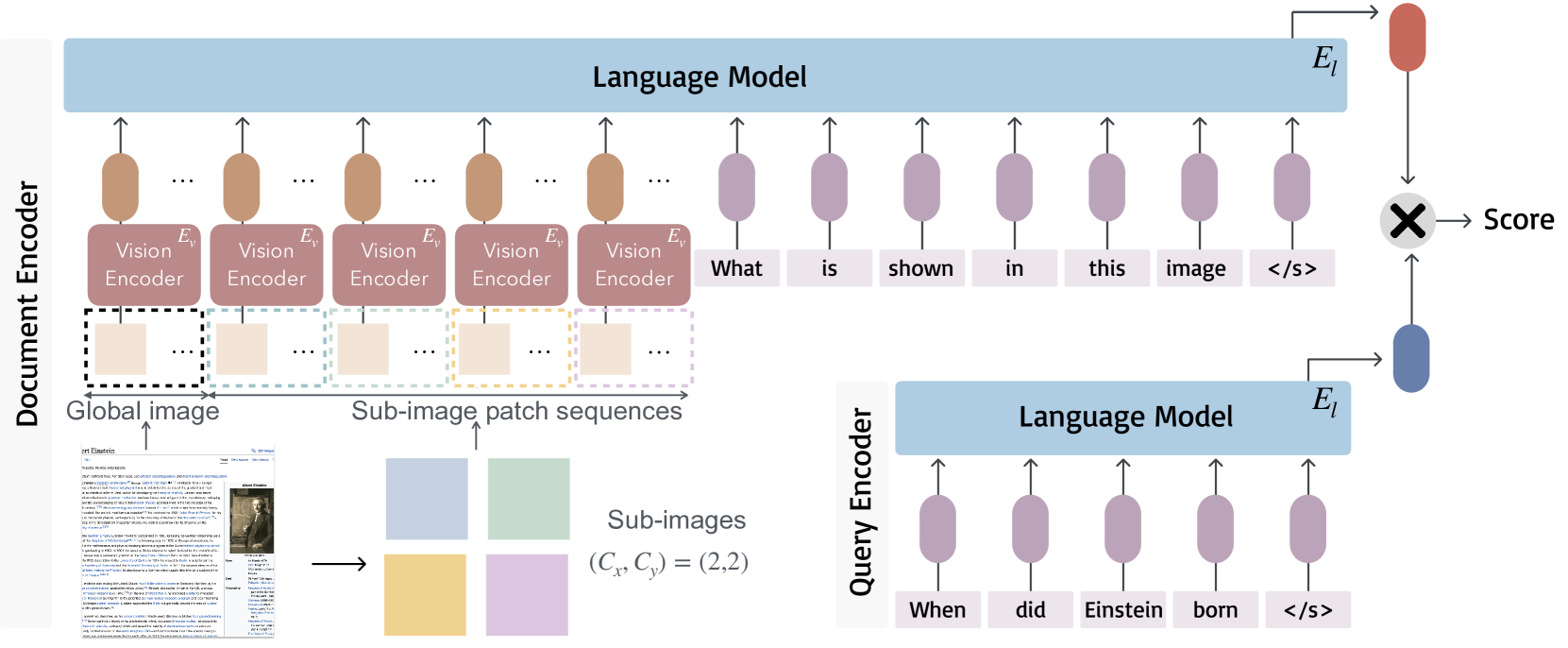
アーキテクチャ
具体的なアーキテクチャは、双方向エンコーダ構造を採用しています。文書タワーはスクリーンショットを、クエリタワーはテキストクエリをそれぞれベクトル表現に変換し、そのコサイン類似度を計算することで関連度を評価します。
LVLMの進化がDSEの革新を支えていると言っても過言ではありません。今後、更に強力なLVLが登場すれば、DSEの精度も飛躍的に向上するでしょう。
視覚エンコーダの進化:パッチ分割とPhi-3-visionの採用
DSEの視覚エンコーダは、スクリーンショットを小さなパッチに分割し、それぞれをLVLMで処理することで、詳細な情報を捉えることを可能にしています。さらに、Phi-3-visionのような高性能なLVLMを採用することで、従来のCLIPベースの手法よりも高い精度を実現しています。Phi-3-visionは、画像をサブ画像に分割して処理することで、より詳細な情報を抽出できることが大きな強みです。
Phi-3-visionの採用は大きな進化ですね。パッチ分割と組み合わせることで、複雑なレイアウトの文書でも高精度な検索が可能になるでしょう。
対照学習による最適化:InfoNCE損失で精度向上
DSEの学習には、InfoNCE損失が用いられます。これは、正例(関連する文書)と負例(無関係な文書)の類似度を最大化するようにモデルを学習させることで、検索精度を向上させる手法です。
LVLMと対照学習の組み合わせは最強タッグ!DSEの驚異的なパフォーマンスを支える重要な要素と言えるでしょう。
妥協なき検証:多様なデータセットによる徹底評価
DSEの性能は、多様なデータセットを用いた徹底的な実験によって検証されています。以下に、主要な結果をまとめます。
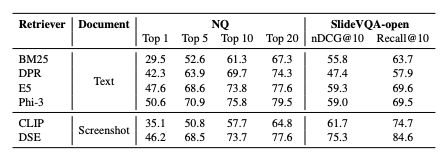
Wikipedia Webページ検索 (テキスト中心)
130万枚のスクリーンショットからなる大規模データセットWiki-SSとNatural Questionsデータセットを用いて評価。BM25と比較してTop-1精度で17ポイント、Top-20精度で10ポイントの向上。
スライド検索 (テキストと画像の混在)
SlideVQAデータセットをオープンな検索タスクに変換し、5万枚のスライドから検索。OCRベースのテキスト検索手法と比較して、nDCG@10で15ポイント以上もの大幅な精度向上。
これらの結果は、DSEがテキスト中心の文書だけでなく、画像を含む複雑な文書に対しても高い検索精度を達成できることを示しています。
多様なデータセットでの検証は素晴らしいですね。これだけの精度向上は、実用化に向けて大きな期待を抱かせます!
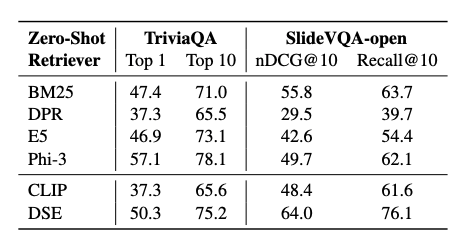
ゼロショット学習:汎化性能の高さを実証
さらに、DSEはゼロショット学習においても優れた性能を発揮することが確認されています。NQデータセットで学習したモデルを、TriviaQAデータセットとSlideVQAデータセットに適用した結果、既存手法を上回る、あるいは匹敵する性能を示しました。これは、DSEが特定のタスクに過剰に最適化されることなく、高い汎化性能を持つことを示唆しています。
ゼロショット学習での高性能は、DSEの適応力の高さを示しています。様々な分野への応用が期待できそうですね!
パッチサイズと処理速度のトレードオフ:最適なバランスを探る
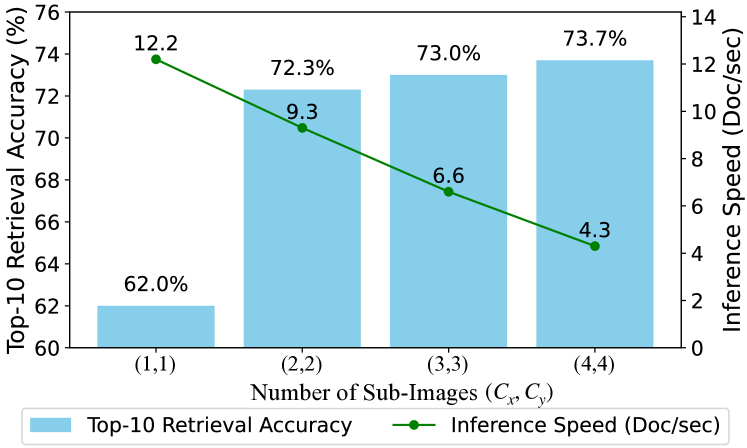
スクリーンショットを分割するパッチのサイズ(Cx, Cy)は、検索精度と処理速度に影響を与えます。パッチサイズを小さくすると、より細かい情報を捉えることができるため精度が向上する一方、計算コストが増加するため処理速度が低下します。論文では、(Cx, Cy) = (2,2) または (3,3) が精度と速度のバランスが良いことを実験的に示しています。(4,4)では精度が向上するものの速度が低下し、(1,1)では速度は速いものの精度が低下します。このトレードオフを理解し、適切なパッチサイズを選択することが重要です。
精度と速度のバランスは常に課題ですね。最適なパッチサイズを見つけることで、DSEの真価が発揮されるでしょう。
ケーススタディ:アテンションの可視化による動作解析
論文では、DSEが実際にどのような情報を捉えているのかを理解するために、アテンションの可視化を行っています。WikipediaとSlideVQAの例を用いて、最終層のマルチヘッドアテンションを可視化した結果、DSEがテキストだけでなく、画像、キャプション、表など、様々なモダリティの情報を効果的に捉えていることが確認されました。これは、DSEが高い検索精度を達成できる理由を裏付ける重要な知見です。
アテンションの可視化は、DSEの内部動作を理解する上で非常に役立ちますね。今後の研究開発にも繋がる貴重な情報です。
エラー分析:更なる改善に向けた課題
高精度なDSEといえども、完璧ではありません。論文では、エラー分析を通じてDSEの限界と今後の改善点についても考察しています。例えば、現状の評価指標では、本文以外の領域(画像キャプションや表など)に含まれる正解が考慮されていないため、DSEの真の性能が過小評価されている可能性が指摘されています。
エラー分析は、今後のDSEの発展に不可欠です。課題を克服することで、更なる精度向上が期待されます。
ビジネスインパクト:様々な分野での応用可能性
DSEは、その革新的なアプローチにより、様々なビジネスシーンでの応用が期待されています。
1 顧客対応
顧客からの問い合わせに対して、FAQやマニュアルなどから最適な回答を迅速に提示。
2 市場調査
膨大な市場データから必要な情報を効率的に収集・分析。
3 コンテンツ制作
関連する資料や画像を迅速に検索し、コンテンツ作成を効率化。
DSEは、これらの業務を自動化・効率化することで、企業の生産性向上に大きく貢献する可能性を秘めています。
顧客対応、市場調査、コンテンツ制作…様々な分野での応用が期待されますね。ビジネスシーンを大きく変革する可能性を感じます。
今後の展望:更なる進化と社会実装への期待
DSEは、まだ発展途上の技術ですが、そのポテンシャルは計り知れません。今後の研究開発において、以下の点が期待されます。
- 多様な文書形式への対応: 現状はWebページやスライドに限定されているため、PDFやその他の文書形式への対応が求められます。
- 対照学習による事前学習: 事前学習によって、更なる精度向上やゼロショット性能の向上が期待されます。
- 低品質画像への対応: ぼやけた画像や低解像度画像でも高い精度を維持できるようなロバスト性の向上が課題となります。
これらの課題を克服することで、DSEは真の意味でマルチモーダル検索の標準技術となり、私たちの生活やビジネスを大きく変革していくことでしょう。
DSEは情報検索の未来を担う技術!今後の進化から目が離せません。更なる発展と社会実装に期待大です!



