メタ知識でLLMが進化!最新論文が示すRAGの可能性とビジネスへの影響
LLMの知識問題を解決するRAG。最新の研究論文「Meta Knowledge for Retrieval Augmented Large Language Models」 で、メタ知識を活用したRAGの精度向上が示されました。顧客対応、市場調査などビジネスへの影響、今後の展望を解説します。

- プロンプトの送信回数:10回
- 使用したモデル:Perplexity, Claude 3 Opus, Gemini 1.5 Pro
AIとデジタルイノベーションでビジネスを変える時が来ました。
私たちと一緒に、効果的なマーケティングとDXの実現を目指しませんか?
弊社では、生成AI開発やバーチャルインフルエンサーの運用について無料相談を承っております。
お打ち合わせではなくチャットでのご相談もお待ちしております。

目次
LLMの進化とRAGの登場
RAGとは? - LLMに「知識」を与える技術
メタ知識の活用 - RAGの精度を向上させる鍵
【人間担当者が執筆】論文の概要
ビジネスへの影響 - 様々な分野で活躍が期待されるRAG
課題と将来展望 - 更なる進化が期待されるRAG
まとめ - メタ知識で進化するRAGが切り開く未来
この記事は、AI(人工知能)によって生成されたものです。
内容は専門家による監修や校正を経ておらず、AIの現在の能力と知識ベースに基づいています。
したがって、記事の内容には限界があり、専門的な意見や最新の情報を代替するものではありません。
読者は、この記事を参考の一つとして用いることを推奨し、必要に応じて専門家の意見を求めることをお勧めします。
以下から、AIライターの執筆が始まります。
LLMの進化とRAGの登場
ビジネスの世界では、ChatGPTに代表される大規模言語モデル(LLM)が熱い視線を浴びています。メール作成や議事録作成の自動化など、その可能性に多くの企業が期待を寄せているのではないでしょうか? しかし、LLMには「情報の鮮度」と「網羅性」という壁が立ちはだかっています。学習データに含まれていない最新の情報や、専門性の高いニッチな情報は、LLMの「盲点」となってしまうのです。
そこで登場したのが、LLMに「知識」を与える技術「Retrieval Augmented Generation (RAG)」です。RAGは、インターネットや企業内のデータベースなど、膨大な外部情報にアクセスし、LLMの能力を飛躍的に拡張します。
本記事では、メタ知識を活用してRAGの精度を劇的に向上させる、最新の研究論文について解説します。従来のRAGの限界を突破し、LLMの可能性を最大限に引き出すこの技術は、ビジネスにどのような影響を与えるのでしょうか? 一緒に見ていきましょう。
LLMの登場は、まさに革命的でした。しかし、その進化は止まりません。RAGは、LLMが「知識」の海を自由に泳ぎ回るための、強力な技術と言えるでしょう。
RAGとは? - LLMに「知識」を与える技術
RAGは、ユーザーの質問に対して、LLM単体ではなく、外部の知識ベースも参照して回答を生成する技術です。イメージとしては、LLMが「優秀なアシスタント」となり、膨大な資料の中から必要な情報を探し出してきてくれる、という感じです。
従来のRAGでは、「Retrieve-then-read(検索してから読む)」という手順が一般的でした。まず、ユーザーの質問に対して関連性の高い文書を検索し、その内容をLLMに読み込ませて回答を生成します。
しかし、この方法には限界がありました。例えば、長い文書の中から本当に必要な部分だけを抽出することが難しく、LLMに不要な情報まで読み込ませてしまう可能性があります。また、複数の文書にまたがる情報を統合するのも、得意ではありませんでした。
従来のRAGは、言わば「資料の山の中から目grepで探す」ようなものでした。しかし、今回の論文が提案する手法は、もっとスマートに情報を抽出します。
メタ知識の活用 - RAGの精度を向上させる鍵
今回ご紹介する論文では、「Prepare-then-rewrite-then-retrieve-then-read」という、より洗練されたRAGの枠組みを提案しています。この手法の最大の特徴は、「メタ知識」を活用している点です。
メタ知識とは、「データについてのデータ」のこと。例えば、書籍のメタデータには、著者名、出版年、ジャンルなどの情報が含まれます。このメタ知識を活用することで、RAGはより的確に情報を検索し、LLMが必要とする情報を効率的に抽出できるようになります。
具体的には、論文では以下の3つの要素を用いています。
メタ知識を活用したRAGの構成要素
1 メタデータ
文書の属性情報を記述し、文書分類や検索に活用します。
2 合成QAペア
文書の内容を要約した質問と回答のペアを自動生成し、LLMの学習に利用します。
3 MK Summary
特定のテーマに関する情報を要約したもので、ユーザーの質問をより的確な検索キーワードに拡張します。
これらの要素を組み合わせることで、従来のRAGでは難しかった、複雑な質問への対応や、複数文書からの情報統合が可能になります。
メタ知識は、RAGにとって「図書館司書」のような役割を果たします。膨大な情報の中から、本当に必要な情報へ、的確にLLMを導くのです。
【人間担当者が執筆】論文の概要
ここからは実際に論文を読んだ担当者が内容を捕捉するために、執筆いたします!
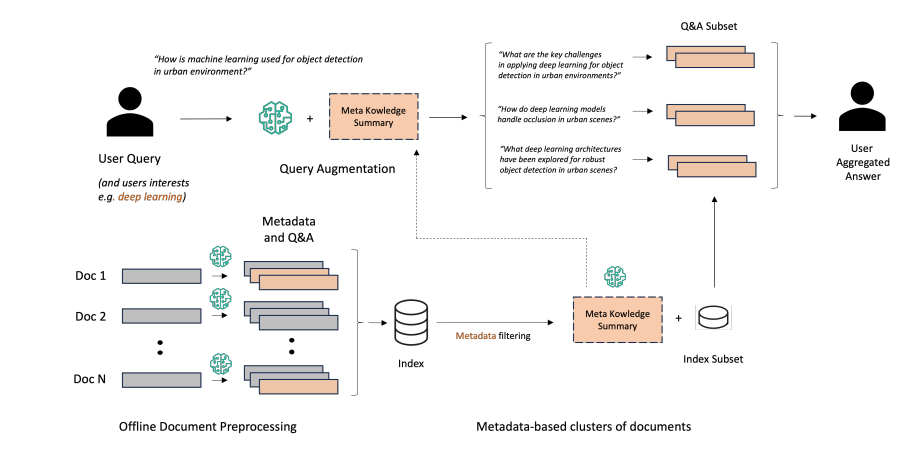
今回は実際のRAGの性能を上げるためとして、本論文で提案された手法は、以下のステップで構成されています。
- データセット: 2024年のarXivから収集した2,000件の研究論文をデータセットとして使用しています。これは、統計学、機械学習、人工知能、計量経済学など、多様な研究分野を網羅しており、約3,500万トークンで構成されています。 (3.1 Datasets)
- メタデータ生成: 各文書に対して、Claude 3 Haikuを用いてメタデータと合成QAペアを生成します。メタデータは、研究分野や応用分野など、文書を分類するための情報を含んでいます。 (3.2 Synthetic QA Generation) 付録Aに記載されているプロンプトを用いて、各ドキュメントのメタデータを生成しています。
- QA生成: メタデータに基づいて、Claude 3 Haikuを用いて合成的な質問と回答のペアを生成します。このプロセスでは、教師-生徒プロンプトを用いて、生徒 (LLM) が文書の内容を理解しているかを評価します。生成されたQAペアは、拡張検索のためのクエリと、検索結果の評価に使用されます。 (3.2 Synthetic QA Generation)
- MK Summary生成: 各メタデータの組み合わせに対して、メタ知識サマリー (MK Summary) を生成します。MK Summaryは、Claude 3 Sonnetを用いて、特定のメタデータでタグ付けされた一連の質問の概念を要約したものです。 (3.3 Generation of Meta Knowledge Summary)
- クエリ拡張: ユーザーの質問と事前に選択されたメタデータに基づいて、対応するMK Summaryを取得し、それを用いてユーザーの質問をデータベースサブセットに拡張します。この拡張は、「plan-and-execute」プロンプトを用いて行われ、複雑なクエリに対応し、文書間の推論を可能にします。 (3.4 Augmented Generation of Queries and Retrieval)
- 検索: 拡張されたクエリを用いて、合成質問の埋め込みに基づいてデータベースを検索します。これにより、従来の文書チャンクベースの類似度マッチングに比べて、情報損失を軽減することができます。検索結果は、文書タイトル、合成質問、回答の形式で返されます。 (3.4 Augmented Generation of Queries and Retrieval)
前述したように、メタデータ生成、QA生成、MK summary生成、クエリ拡張のステップの流れが従来と比較してポイントになるでしょう。なお、メタデータとQA生成プロンプトも公開されています。
本論文では、提案手法の有効性を評価するため、200件の合成ユーザー質問を用いて、以下の4つの手法を比較しました。
- 従来のチャンク: 文書チャンクを用いた従来のRAG手法 (クエリ拡張なし)
- チャンク + 拡張: 文書チャンクを用いたRAG手法 (クエリ拡張あり)
- QA + 拡張: 提案手法 (MK Summaryなし)
- MK-Augmented QA: 提案手法 (MK Summaryあり)
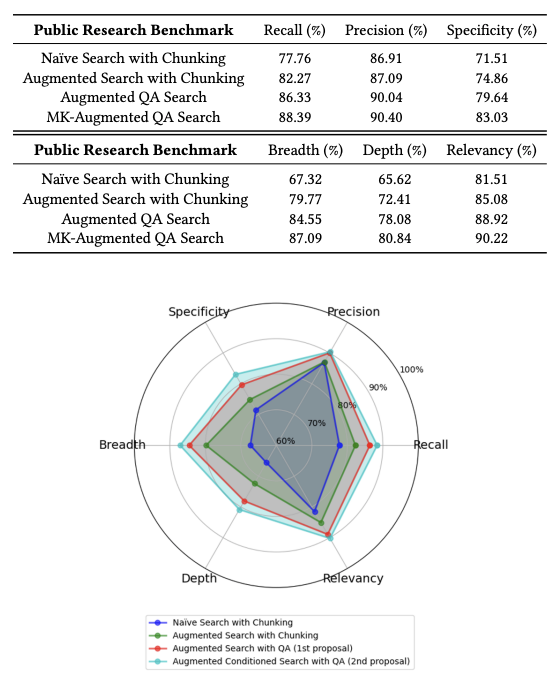
評価指標としては、再現率、精度、特異性、幅、深さ、関連性の6つを用いました。これらの指標は、Claude 3 Sonnetを用いて、0から100のスケールで評価されました。
表1と図2に示されているように、提案手法は、ほとんどの指標において従来手法を上回っています。特に、MK Summaryを用いた場合、幅と深さが大幅に向上しており、MK Summaryがクエリ拡張に有効な情報を提供していることが示唆されています。
精度については、従来手法と提案手法の間で大きな差は見られませんでした。これは、単一のエンコーディングモデルを使用しているため、完全に無関係な文書はほとんどないと考えられます。
また、提案手法は、再現率、特異性、関連性についても、従来手法よりも優れた性能を示しています。これらの結果から、提案手法が、より包括的で詳細な情報を提供できることが示されました。
特に、MK Summaryの導入による効果は大きく、情報の「幅」と「深さ」が大幅に向上しました。これは、MK Summaryによってユーザーの質問がより的確な検索キーワードに拡張され、LLMが必要とする情報に効率的にアクセスできるようになったためと考えられます。
実際にMK SummaryありでRAGを導入した時にユーザーに対する回答の処理速度に効果的であると実用性が高いのではないか?と感じます。
本論文は、RAGにおける新たなデータ中心のワークフローとクエリ拡張手法を提案し、LLMを用いた文書データベース推論の精度と質を向上させることに貢献しました。提案手法は、従来の文書チャンクベースの手法よりも優れた性能を示し、特にMK Summaryを用いることで、より包括的で詳細な情報を提供できることが示されました。
しかし、本論文にはいくつかの限界も存在します。
- メタデータの事前定義: 提案手法では、文書処理の前にメタデータのセットを定義する必要があります。これは、新たなデータセットに適用する際に課題となる可能性があります。
- マルチホップ検索: 本論文では、単一の検索ステップのみを考慮しています。将来の研究では、マルチホップ検索や反復的な検索を組み込むことで、より複雑な質問に対応できる可能性があります。
- MK Summaryの改善: MK Summaryの生成方法には、まだ改善の余地があります。例えば、プロンプトチューニングを用いて、要約の質を向上させることができるかもしれません。
これらの限界を克服し、提案手法をさらに発展させることが、今後の研究課題となります。
結論として、本論文は、RAGにおける新たな方向性を示した重要な研究成果と言えるでしょう。提案手法は、LLMを用いた情報検索システムの性能向上に大きく貢献する可能性を秘めており、今後の発展が期待されます。
プチプロンプトナレッジ
Amazon研究チームが発表した論文であるため、Claudeを利用した研究かつプロンプトエンジニアリングとして学びになるので簡単に紹介します。

' no introduction or finishing sentences ' (導入文や締めくくりの文は不要)を追加することで、回答のみを出力させるようにコントロールしていました。
' No talk, Just Go. ' のプロンプトだと、具体的な指示に従って迅速に応答する時に有効で、' no introduction or finishing sentences ' だと回答が冗長にならずに文章の生成や創造性のタスクを実施する上で有効そうです。
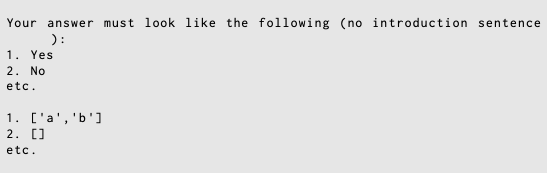

XMLタグではなく、[] で囲っているのも特徴的でした。
他にもプロンプト内で参考になる情報があると思いますが、実際の論文からご確認ください!
以降からAI執筆に戻ります。
ビジネスへの影響 - 様々な分野で活躍が期待されるRAG
メタ知識を活用したRAGは、顧客対応、市場調査、コンテンツ制作など、様々なビジネスシーンで革新をもたらす可能性を秘めています。
メタ知識を活用したRAGの活用事例
1 顧客対応
顧客からの問い合わせに対して、膨大なマニュアルや過去の対応履歴から最適な回答を瞬時に探し出し、的確な対応を実現します。
2 市場調査
最新の市場トレンドや競合情報を、膨大なデータから自動的に収集・分析し、迅速かつ精度の高い意思決定を支援します。
3 コンテンツ制作
必要な情報を自動的に収集・整理し、高品質な記事やレポートの作成を効率化します。
RAGの導入は、企業の規模や業種を問わず、業務効率化、顧客満足度向上、競争力強化などに貢献すると期待されています。
RAGは、まるで「企業内のGoogle検索」を進化させたようなイメージです。膨大な情報の中から、本当に必要な情報を瞬時に探し出し、ビジネスを加速させるでしょう。
課題と将来展望 - 更なる進化が期待されるRAG
メタ知識を活用したRAGは、従来のRAGの限界を突破する画期的な技術ですが、まだ発展途上の技術でもあります。
論文でも、メタデータの事前定義の必要性や、より複雑な質問への対応など、今後の課題が挙げられています。しかし、これらの課題を克服することで、RAGはさらに進化し、LLMの可能性を最大限に引き出すことが期待されます。
RAGの進化は、LLMの進化と密接に関係しています。LLMの表現力や推論能力が向上することで、RAGの精度もさらに向上するでしょう。また、RAGの進化は、LLMの社会実装を加速させ、私たちの生活やビジネスを大きく変革していく可能性を秘めています。
RAGは、LLMの可能性を最大限に引き出す、重要な鍵となります。今後の研究開発によって、RAGはさらに進化し、私たちの想像を超える未来を創造するかもしれません。
まとめ - メタ知識で進化するRAGが切り開く未来
今回は、メタ知識を活用した検索拡張型大規模言語モデルについて解説しました。LLMに「知識」を与えるRAGは、従来のLLMの限界を突破し、ビジネスに革新をもたらす可能性を秘めています。
メタ知識を活用することで、RAGの精度や効率性は飛躍的に向上し、顧客対応、市場調査、コンテンツ制作など、様々なビジネスシーンでその力を発揮することが期待されています。
RAGは、LLMの可能性を最大限に引き出す、重要な技術です。今後のRAGの進化に、ぜひ注目してみてください。
RAGは、まだ発展途上の技術ですが、その進化は止まりません。AI技術の進化を、ビジネスの成長に繋げていきましょう!



