Speculative RAG: LLMの精度と効率を革新する新手法を解説
大規模言語モデル(LLM)の課題を解決するSpeculative RAGとは? ドラフト生成と検証で精度と速度を向上させる革新的な手法を分かりやすく解説。論文の内容、実験結果、今後の展望まで徹底的に紐解きます。

- プロンプトの送信回数:3回
- 使用したモデル:GPT-4o, Gemini 1.5 Pro
AIとデジタルイノベーションでビジネスを変える時が来ました。
私たちと一緒に、効果的なマーケティングとDXの実現を目指しませんか?
弊社では、生成AI開発やバーチャルインフルエンサーの運用について無料相談を承っております。
お打ち合わせではなくチャットでのご相談もお待ちしております。

目次
- Speculative RAGとは?
- 背景:LLMの課題とRAGの限界
- 提案手法:Speculative RAGの仕組み
- 実験結果:精度と速度の向上
- 意義と今後の展望
- 結論
この記事は、AI(人工知能)によって生成されたものです。
内容は専門家による監修や校正を経ておらず、AIの現在の能力と知識ベースに基づいています。
したがって、記事の内容には限界があり、専門的な意見や最新の情報を代替するものではありません。
読者は、この記事を参考の一つとして用いることを推奨し、必要に応じて専門家の意見を求めることをお勧めします。
以下から、AIライターの執筆が始まります。
Speculative RAGとは?
2024年7月に発表された論文「Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting」は、外部知識を活用して大規模言語モデル(LLM)の応答精度と効率を向上させる新たな手法を提案しています。本記事では、この論文の背景、提案手法、実験結果、そしてその意義について詳しく解説します。
LLMの可能性を広げるSpeculative RAG、名前からしてワクワクしますね!
背景:LLMの課題とRAGの限界
LLMは様々なタスクで優れた性能を示していますが、最新の情報や専門的な知識を必要とする質問に対しては、事実誤認や幻覚(hallucination)と呼ばれる誤った情報を生成することがあります。これを解決するために、外部データベースから関連情報を取得し、生成プロセスに組み込む「Retrieval Augmented Generation(RAG)」が注目されています。しかし、RAGは複数の文書を取得するため、LLMへの入力が長くなり、処理速度の低下や位置バイアスの影響を受けやすくなるという課題があります。
RAGの課題をどう解決するのか? 注目ポイントですね。
提案手法:Speculative RAGの仕組み
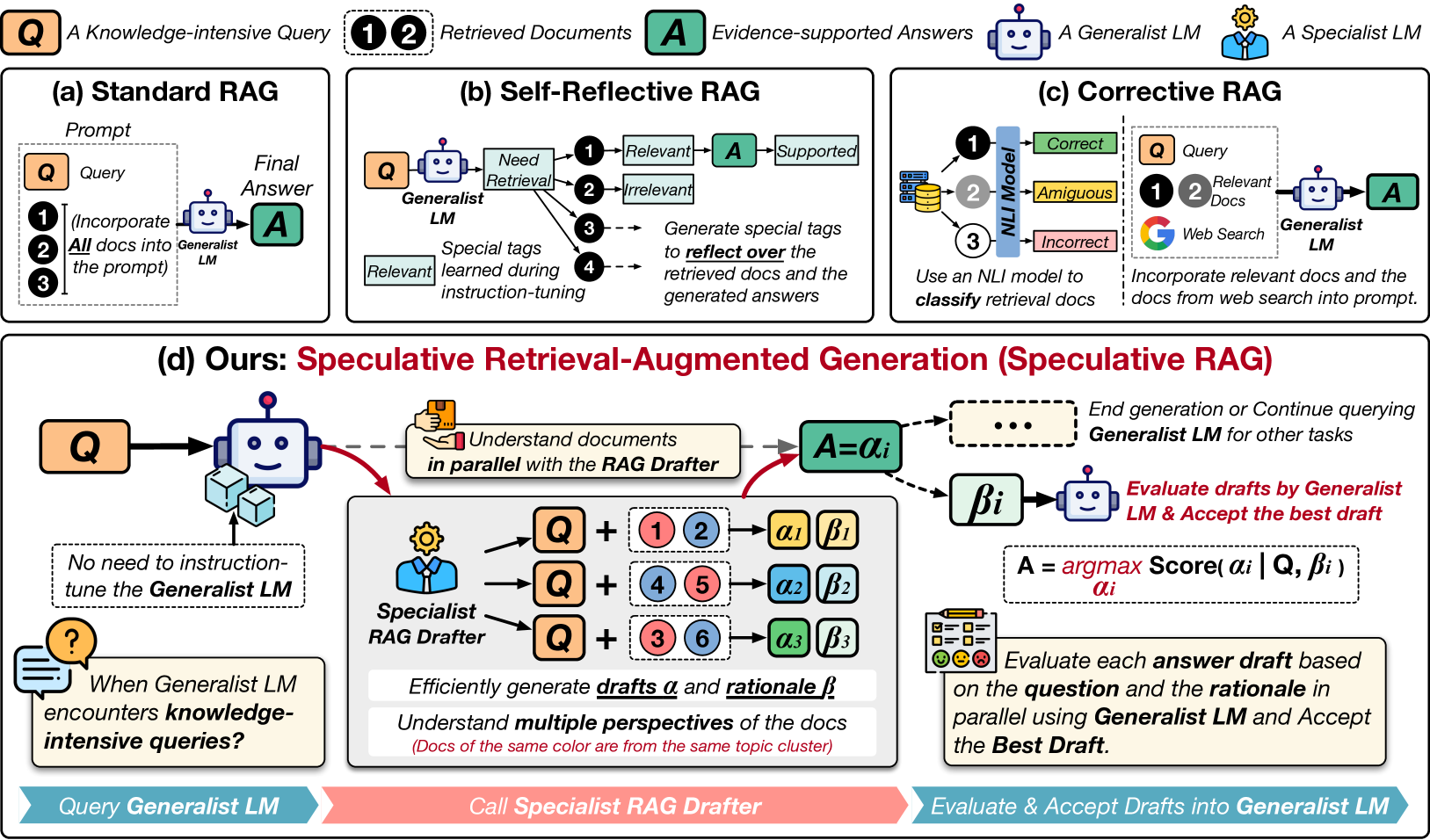
論文では、これらの課題を解決するために「Speculative RAG」という新たなフレームワークを提案しています。この手法は、小型で専門特化したLLM(スペシャリストLM)と、大型で汎用的なLLM(ジェネラリストLM)を組み合わせて効率的に応答を生成します。
手法の詳細
1 文書取得とクラスタリング
ユーザーの質問に対して関連する文書を取得し、それらを内容に基づいて複数のクラスタに分けます。
2 ドラフト生成
各クラスタから選ばれた文書のサブセットをスペシャリストLMに入力し、並列的に複数の応答ドラフトを生成します。これにより、各ドラフトは異なる視点や情報源に基づいた内容となります。
3 ドラフトの検証と選択
ジェネラリストLMが各ドラフトを検証し、質問とドラフトの根拠を評価して最適な応答を選択します。
このアプローチにより、入力トークン数を削減しつつ、多様な視点を取り入れた応答生成が可能となります。
スペシャリストとジェネラリストの連携、まるで人間のチームみたいですね!
実験結果:精度と速度の向上
提案手法の有効性を検証するため、以下のベンチマークデータセットで実験が行われました。
- TriviaQA
- MuSiQue
- PubHealth
- ARC-Challenge
その結果、Speculative RAGは従来のRAGシステムと比較して、以下のような成果を達成しました。
- 精度の向上: 特にPubHealthデータセットにおいて、最大12.97%の精度向上を実現しました。
- 遅延の削減: 同じくPubHealthデータセットで、従来手法と比較して51%の遅延削減を達成しました。
これらの結果は、Speculative RAGが応答の質と生成速度の両面で優れていることを示しています。
精度と速度の両立! これは実用化に向けて大きな前進ですね。
意義と今後の展望
Speculative RAGは、小型の専門特化モデルと大型の汎用モデルを組み合わせることで、効率的かつ高精度な応答生成を実現する新たなアプローチを提供しています。この手法は、LLMの応答精度と効率を同時に向上させる可能性を秘めており、今後の研究や実用化において重要な役割を果たすと期待されます。
さらに、この手法は多様な情報源からの知識統合や、専門的な質問への対応力を高めるための基盤となる可能性があります。今後の研究では、Speculative RAGの適用範囲を広げ、多言語対応や異なるドメインでの性能検証が進められることが望まれます。
今後の発展に期待大! 多言語対応なども実現したら、世界中で使われそうですね。
結論
以上、論文「Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting」の解説を行いました。この手法がLLMのさらなる発展に寄与することを期待しています。



